Significance Tests for Covariates in LCA and LTA
I am performing LCA and wondered how to test the significance of my covariates. I understand that I need a test statistic and its corresponding degrees of freedom (df) to perform the test, but I don’t know how to get this information from my output. ––Signed, Feeling Insignificant
LCA vs Factor Analysis: About Indicators
My understanding is that when an indicator has no relation to the latent construct of interest, this is represented differently in LCA than in factor analysis. Can you explain how and why this works? ––Signed, Latently Lost
Factorial Experiments
I am interested in Dr. Collins’ work on optimizing behavioral interventions, and I was surprised that she advocates the use of factorial experimental designs for some experiments. I was taught that factorial experiments could never be sufficiently powered. Can factorial designs really be implemented in practice? — Signed, Fretting Loss of Power
Dear FLOP,
This is a common question. Experimental subjects are often expensive or scarce. In these cases, a factorial experiment can save money and resources and still provide sufficient statistical power.
Dr. Welton is revamping a high-risk teen drinking intervention to be delivered in mental health settings, and she is deciding which of the following components to add: (A) peer-based sessions; (B) parent-based sessions; (C) drug resistance skills; and/or (D) drug use education. Dr. Welton wants to decide which combination of the new components will achieve the best participant adherence. Dr. Welton considers two different design approaches:
- Conduct four separate experiments, one corresponding to each of the intervention components. Each experiment would involve two conditions: (i) a condition in which the intervention component is included, and (ii) a control condition in which the intervention component is not included. For each of the four experiments, the data analysis would produce an estimate of the mean difference between the two conditions.
- Conduct a factorial experiment. This approach would treat each of the four components as a factor (i.e., independent variable) that can take on the levels “not included” or “included.” Crossing these factors would result in 16 experimental conditions (every combination of the levels of the four factors) and provide estimates of the main effect of each component and all interactions between components.
Next, Dr. Welton considers the cost of each approach. She anticipates a per-subject cost of $100. In addition, the overhead associated with each experimental condition (except for the control condition) will be $500, which is the cost of developing materials and training staff for each new version of the intervention. She specifies that each component has to produce an effect of at least .35 of a standard deviation in order to be considered for inclusion in the new intervention. Therefore, Dr. Welton wants to be sure she has the power to detect effects of at least this size.
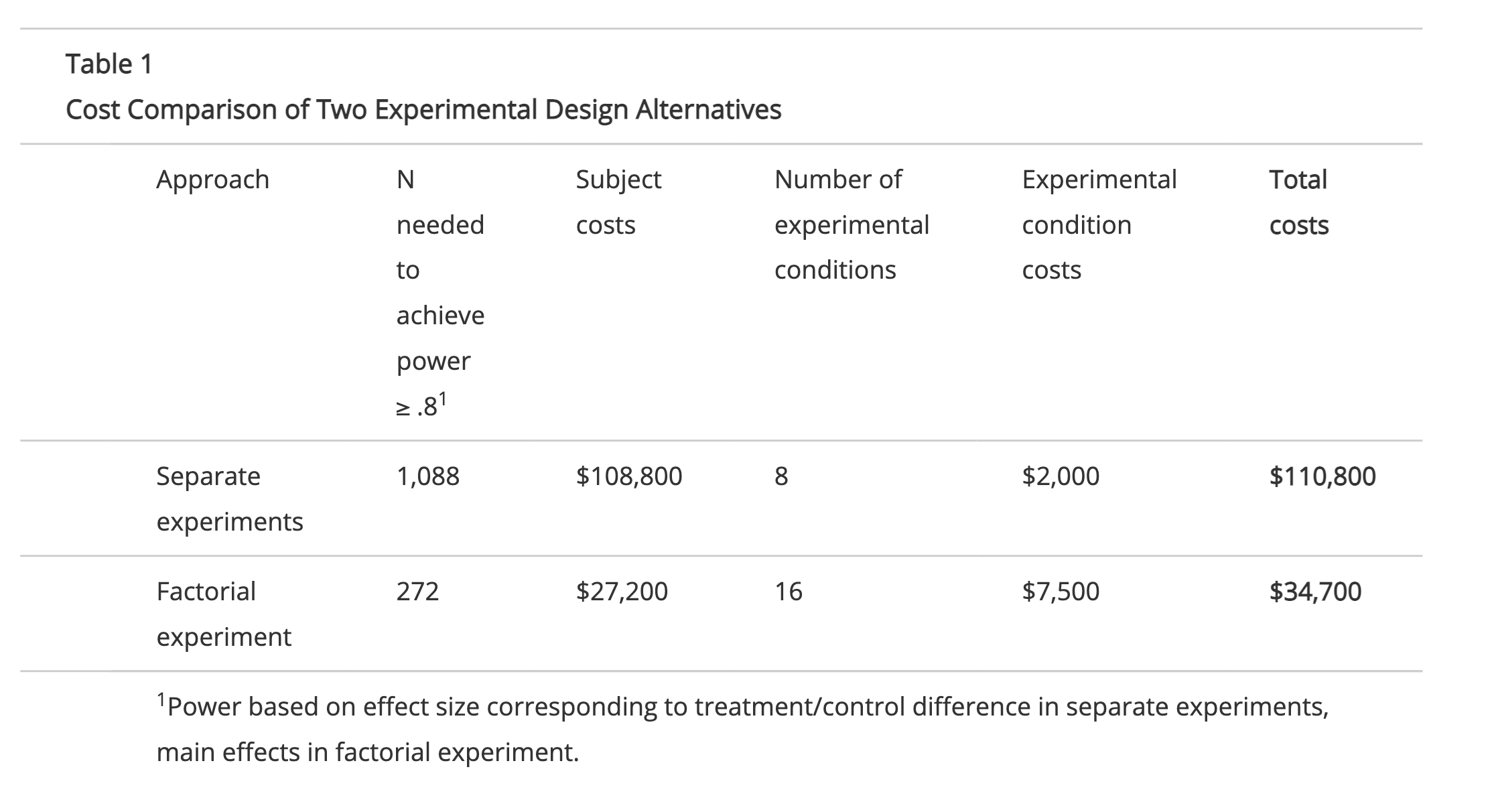
Table 1 compares the cost of each approach. To achieve the desired statistical power in this example, the separate experiments approach requires four times as many subjects as the factorial experiment. Dr. Welton would save $76,100 by conducting a factorial experiment instead of four separate experiments! Collins, Dziak, and Li (2009) discuss how to determine which of several design alternatives is most cost-effective in a given situation. A free SAS macro for comparing the relative costs of a variety of experimental designs can be found here.
Analyzing EMA Data
I designed a study to assess 50 college students’ motivations to use alcohol and its correlates during their first semester. The most innovative part of this study was that I collected data with smart phones that beeped at several random times on every Thursday, Friday, and Saturday throughout the semester. Now that I’ve collected the data, I’m overwhelmed by how rich the data are and don’t know where to start! My first thought is to collapse the data to weekly summary scores and model those using growth curve analysis. Is there anything more I can do with the data? — Signed, Swimming in Data
Are Adaptive Interventions Bayesian?
I love the idea of adaptive behavioral interventions. But, I keep hearing about adaptive designs and how they are Bayesian. How can an adaptive behavioral intervention be Bayesian? —Signed, Adaptively Confused, Determined to Continue
Modeling Multiple Risk Factors
I want to investigate multiple risk factors for health risk behaviors in a national study, but do not know how to handle the high levels of covariation among the different risk factors. Do you recommend that I regress the outcome on the entire set of risk factors using multiple regression analysis? Or should I create a cumulative risk index by summing risk exposure, and regress the outcome on that index? — Signed, Waiting to Regress
Handling Time-Varying Treatments
I’ve heard about new methodologies being developed that allow scientists to address novel scientific questions concerning the effects of time-varying treatments or predictors using observational longitudinal data. What are some examples of these scientific questions, and where can I read up on these newer methodologies? —Signed, Time for a Change
Experimental Designs That Use Fewer Subjects
I am trying to develop a drug abuse treatment intervention. There are six distinct components I am considering including in the intervention. I need to make the intervention as short as I can, so I don’t want to include any components that aren’t having much of an effect. I decided to conduct six experiments, each of which would examine the effect of a single intervention component. I need to be able to detect an effect size that is at least d =.3; any smaller than that and the component would not be pulling its own weight, so to speak. I have determined that I need a sample size of about N=200 for each experiment to maintain power at about .8. But then I did the math and figured out that with six experiments, I would need 6 X 200 = 1200 subjects! Yikes! Is there any way I can learn what I need to know, but using fewer subjects? —Signed, Experimental Design Gives Yips
Fit Statistics and SEM
I am interested in examining the role of three variables (family drug use, family conflict and family bonding) as mediators of the effect of neighborhood disorganization on adolescent drug use. I fit a structural equation model, but wonder which of the many fit statistics I should report?— Signed, Befuddled by Fit
Modeling Behavior Change Over Time
I am interested in modeling change over time in risky sexual behavior during adolescence, but I cannot decide how to code my outcome variable. I could create a dummy variable at each time point that indicates whether or not the individual has had intercourse, a count variable for the number of partners, or a continuous measure of the proportion of times they used a condom, but none of these approaches seems to capture the complex nature of the behavior. — Uni Dimensional
Propensity Scores
I have been hearing a lot lately about propensity scores. What are they, and how can I use them? — Signed, Lost Cause
AIC vs. BIC
I often use fit criteria like AIC and BIC to choose between models. I know that they try to balance good fit with parsimony, but beyond that I’m not sure what exactly they mean. What are they really doing? Which is better? What does it mean if they disagree? — Signed, Adrift on the IC’s
Evaluating Latent Growth Curve Models
I am using a latent growth curve approach to model change in problem behavior across four time points. Although my exploratory analyses suggested that a linear growth function would describe individual trajectories well for nearly all of the adolescents in my sample, the overall model fit (in terms of RMSEA and CFI) is poor. Is my model really that bad? — Signed, Fit to be Tied
Multiple Imputation and Survey Weights
I’m analyzing data from a survey and would like to handle the missing values by multiple imputation. Should the survey weights be used as a covariate in the imputation model? — Signed, Weighting for Your Response
Determining Cost-Effectiveness
If I know the cost associated with administering my substance abuse intervention program, how do I determine whether my program was cost-effective? — Signed, Worried about Bottom Line
Maximum Likelihood vs. Multiple Imputation
Which is better for handling missing data: maximum likelihood approaches like the one incorporated in the structural equation modeling program AMOS, or multiple imputation approaches like the one implemented in Joe Schafer’s software NORM? — Signed, Not Uniformly There

Let’s stay in touch.
We are in this together. Receive an email whenever a new model or resource is added to the Knowledge Base.